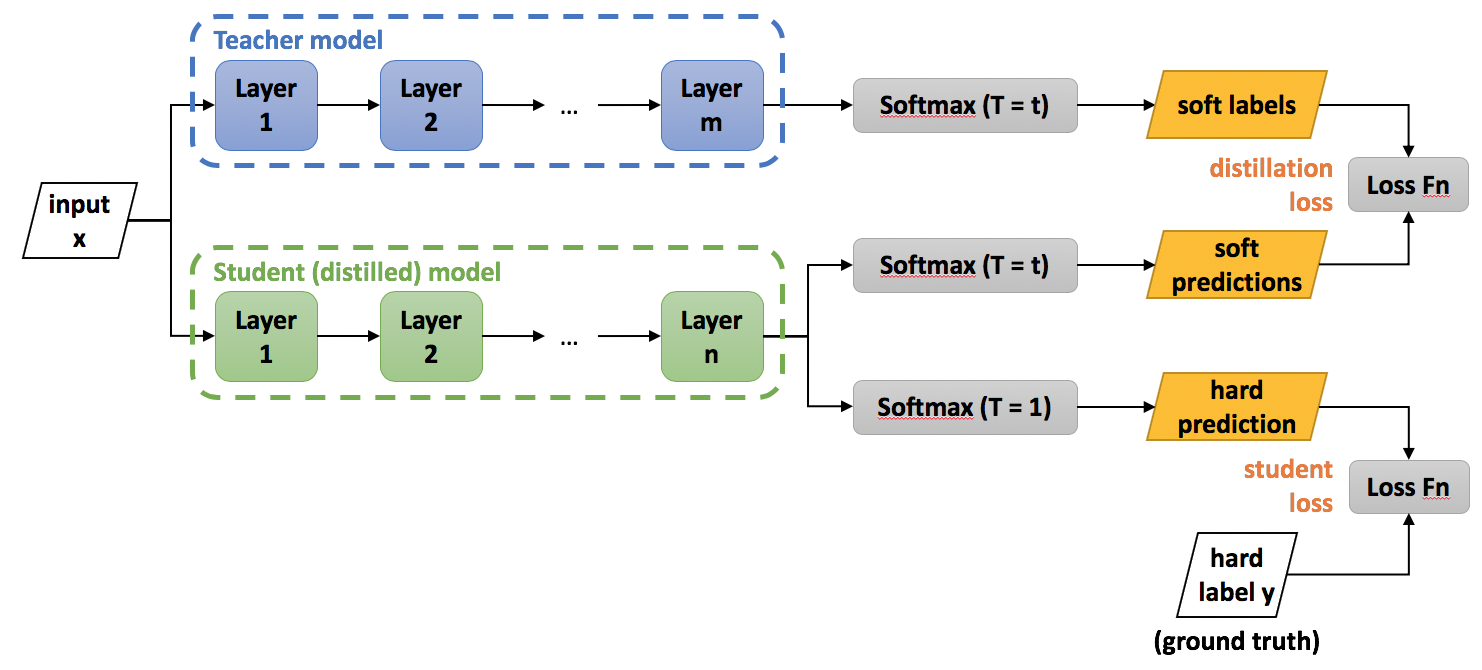
Speech Enhancement Knowledge Distillation . Web tiny, causal models are crucial for embedded audio machine learning applications. Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates and.
from intellabs.github.io
Web tiny, causal models are crucial for embedded audio machine learning applications. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates and.
Knowledge Distillation Neural Network Distiller
Speech Enhancement Knowledge Distillation Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates and. Web tiny, causal models are crucial for embedded audio machine learning applications. Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student.
From www.semanticscholar.org
Figure 1 from MetricGANOKD MultiMetric Optimization of MetricGAN via Speech Enhancement Knowledge Distillation Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates and. Web tiny, causal models are crucial for embedded audio machine learning applications. Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small. Speech Enhancement Knowledge Distillation.
From deepai.org
Breaking the tradeoff in personalized speech enhancement with cross Speech Enhancement Knowledge Distillation Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates and. Web this paper proposes a learning method that dynamically uses knowledge distillation (kd). Speech Enhancement Knowledge Distillation.
From www.researchgate.net
(PDF) Speech Enhancement Using Dynamic Learning in Knowledge Speech Enhancement Knowledge Distillation Web tiny, causal models are crucial for embedded audio machine learning applications. Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates and. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small. Speech Enhancement Knowledge Distillation.
From www.semanticscholar.org
[PDF] Injecting Spatial Information for Monaural Speech Enhancement via Speech Enhancement Knowledge Distillation Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates and. Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web to reduce this computational burden, we propose a unified residual. Speech Enhancement Knowledge Distillation.
From blog.roboflow.com
What is Knowledge Distillation? A Deep Dive. Speech Enhancement Knowledge Distillation Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates and. Web tiny, causal models are crucial for embedded audio machine learning applications. Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse). Speech Enhancement Knowledge Distillation.
From www.programmersought.com
Knowledge Distillation A Survey Programmer Sought Speech Enhancement Knowledge Distillation Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates and. Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web tiny, causal models are crucial for embedded audio machine learning. Speech Enhancement Knowledge Distillation.
From www.mdpi.com
Applied Sciences Free FullText Speech Enhancement Using Generative Speech Enhancement Knowledge Distillation Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web tiny, causal models are crucial for embedded audio machine learning applications. Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates. Speech Enhancement Knowledge Distillation.
From www.researchgate.net
(PDF) TestTime Adaptation Toward Personalized Speech Enhancement Zero Speech Enhancement Knowledge Distillation Web tiny, causal models are crucial for embedded audio machine learning applications. Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates and. Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation. Speech Enhancement Knowledge Distillation.
From github.com
GitHub ckonst/speechenhancement Neural Speech Enhancement Speech Enhancement Knowledge Distillation Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web tiny, causal models are crucial for embedded audio machine learning applications. Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates. Speech Enhancement Knowledge Distillation.
From deepai.org
TwoStep Knowledge Distillation for Tiny Speech Enhancement DeepAI Speech Enhancement Knowledge Distillation Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web fortunately, speech enhancement (se) algorithms can enhance these speech. Speech Enhancement Knowledge Distillation.
From www.youtube.com
Knowledge Distillation in Deep Learning DistilBERT Explained YouTube Speech Enhancement Knowledge Distillation Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates and. Web tiny, causal models are crucial for embedded audio machine learning applications. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web. Speech Enhancement Knowledge Distillation.
From deepai.org
Incorporating Ultrasound Tongue Images for AudioVisual Speech Speech Enhancement Knowledge Distillation Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web tiny, causal models are crucial for embedded audio machine. Speech Enhancement Knowledge Distillation.
From neptune.ai
Knowledge Distillation Principles, Algorithms, Applications Speech Enhancement Knowledge Distillation Web tiny, causal models are crucial for embedded audio machine learning applications. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a. Speech Enhancement Knowledge Distillation.
From mayurji.github.io
Knowledge Distillation, aka. TeacherStudent Model Speech Enhancement Knowledge Distillation Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web tiny, causal models are crucial for embedded audio machine learning applications. Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates. Speech Enhancement Knowledge Distillation.
From www.semanticscholar.org
Figure 4 from Speech Enhancement Using Generative Adversarial Network Speech Enhancement Knowledge Distillation Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates and. Web tiny, causal models are crucial for embedded audio machine learning. Speech Enhancement Knowledge Distillation.
From www.mdpi.com
Applied Sciences Free FullText Speech Enhancement Using Generative Speech Enhancement Knowledge Distillation Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web tiny, causal models are crucial for embedded audio machine learning applications. Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates. Speech Enhancement Knowledge Distillation.
From www.researchgate.net
(PDF) Injecting Spatial Information for Monaural Speech Enhancement via Speech Enhancement Knowledge Distillation Web tiny, causal models are crucial for embedded audio machine learning applications. Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a small student. Web fortunately, speech enhancement (se) algorithms can enhance these speech signals, improving recognition rates and. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation. Speech Enhancement Knowledge Distillation.
From www.researchgate.net
Knowledge distillation for nonsemantic speech embeddings. The dotted Speech Enhancement Knowledge Distillation Web this paper investigates how to improve the runtime speed of personalized speech enhancement (pse) networks. Web tiny, causal models are crucial for embedded audio machine learning applications. Web to reduce this computational burden, we propose a unified residual fusion probabilistic knowledge distillation (kd). Web this paper proposes a learning method that dynamically uses knowledge distillation (kd) to teach a. Speech Enhancement Knowledge Distillation.